- 1. Business Problems
- 2. Obtaining Data
- 3. Analyzing Data
- 3.1. Thống kê tổng quan
- 3.2. Ma trận độ tương quan giữa các features
- 3.3. Nghỉ việc vs Lương
- 3.4. Nghỉ việc vs Bộ phận làm việc
- 3.5. Nghỉ việc vs Số lượng project đã tham gia
- 3.6. Nghỉ việc vs Đánh giá
- 3.7. Nghỉ việc vs Thời gian làm việc trung bình trong tháng
- 3.8 Đánh giá vs Độ thoả mãn
- 3.9. Sử dụng K-Means Clustering
- 4. Kết luận
- 5. Tham khảo
Pham Thị vốn là một tập đoàn lớn nhất nhì ở cái đất này. Người đông thế mạnh, tiềm lực tài chính lên đến con số hàng nghìn tỉ, tuấn kiệt như sao buổi tối, nhân tài nhiều như lá rụng mùa thu, trai xinh gái đẹp đủ cả. Thực là o-sằm! 😎
Thế nhưng dạo gần đây xuất hiện nhiều sự lạ, các nhân viên lần lượt ra đi, thậm chí cả những khai quốc công thần từng cống hiến cho Pham Thị từ những ngày đầu. Thực đáng quan ngại! 😨
Ban lãnh đạo tập đoàn đã phải lập tức tiến hành các cuộc họp để tìm ra nguyên nhân tại sao xảy ra tình trạng ấy. Một cuộc điều tra đã được diễn ra với sự vào cuộc của tất cả các phòng ban, và những kết quả được đưa ra thực khiến tất cả mọi người không khỏi bất ngờ 😱
1. Business Problems
“You don’t build a business. You build people, and people build the business.” - Zig Ziglar

Câu chuyện bên trên chỉ là một câu chuyện hư cấu =)) tuy nhiên nó cũng đúng phần nào đối với các công ty. Nhân sự luôn luôn là một vấn đề đau đầu nhất đối với các lãnh đạo. Tìm được người phù hợp đã khó, giữ người còn khó hơn.
Bài phân tích này của mình sẽ nhằm mục đích tìm ra một số điểm “đáng lưu ý” khi nhân viên ra đi, dựa trên dataset Human Resources Analytics được cung cấp bởi Kaggle.
📌 Note: Dữ liệu được xây dựng, không phải dữ liệu thực tế của Pham Thị hay bất cứ công ty nào cả.
Các công cụ: Jupyter Notebook, Python 3.5, Numpy, Pandas, Matplotlib, Seaborn, Scikit-Learn.
2. Obtaining Data
Ta sẽ download dữ liệu csv từ Kaggle về và sau đó sử dụng Pandas để load dữ liệu ra.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as matplot
import seaborn as sns
%matplotlib inline
df = pd.DataFrame.from_csv('../input/HR_comma_sep.csv', index_col=None)Đối với các dữ liệu thống kê nói chung, thì việc thiếu dữ liệu hoặc dữ liệu bị sai là điều khó thể tránh khỏi. Vì thế trước khi phân tích chúng ta đều phải có bước tiền xử lý để hoặc là fill các dữ liệu đó, hoặc là xoá nó đi.
>>> df.isnull().any()
satisfaction_level False
last_evaluation False
number_project False
average_montly_hours False
time_spend_company False
Work_accident False
left False
promotion_last_5years False
sales False
salary False
dtype: boolÔ kê, dữ liệu được chuẩn bị khá là ngon rồi :D
Ta sẽ nhìn lướt qua data một chút để nắm được có những thông tin gì ở đây.
>>> df.head()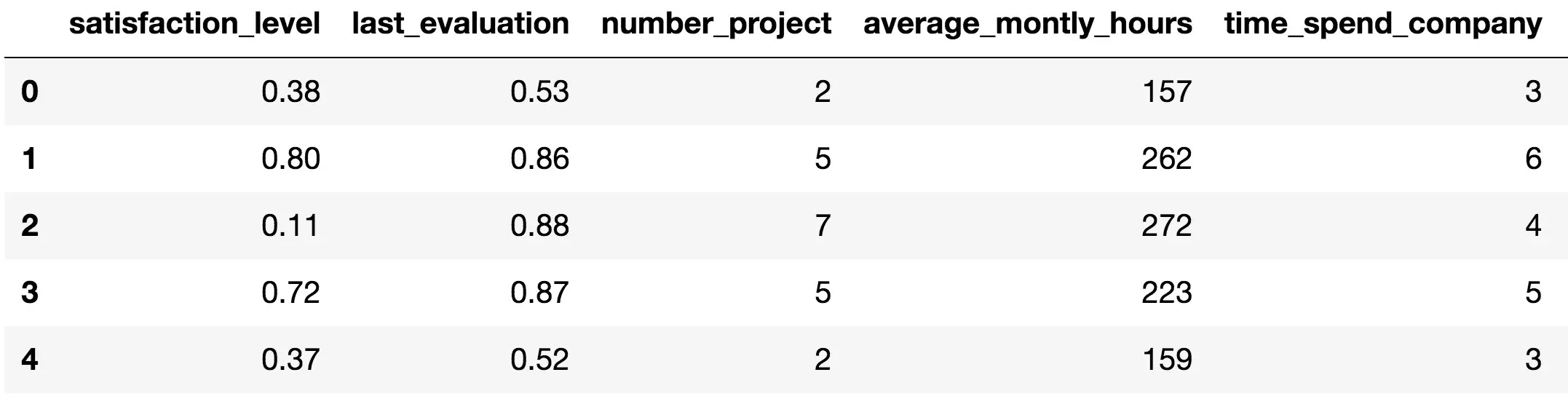 Có tất cả 10 thông tin đối với mỗi nhân viên. Trong đó có rất nhiều thông tin thú vị, như số giờ làm việc trung bình trong tháng, lương cao hay thấp, số project đã làm, số phốt,…
Có tất cả 10 thông tin đối với mỗi nhân viên. Trong đó có rất nhiều thông tin thú vị, như số giờ làm việc trung bình trong tháng, lương cao hay thấp, số project đã làm, số phốt,…
Nhận thấy rằng những tên cột đang là physics name, khá khó cho việc đọc hiểu, nên ta sẽ sửa lại tên các cột một chút cho “thân thiện” như sau:
df = df.rename(columns={'satisfaction_level': 'satisfaction',
'last_evaluation': 'evaluation',
'number_project': 'projectCount',
'average_montly_hours': 'averageMonthlyHours',
'time_spend_company': 'yearsAtCompany',
'Work_accident': 'workAccident',
'promotion_last_5years': 'promotion',
'sales' : 'department',
'left' : 'turnover'
})Trong bài này, ta quan tâm đến việc nhân viên ở lại hay ra đi, nên cột turnover ta sẽ đưa lên đầu cho dễ nhìn
front = df['turnover']
df.drop(labels=['turnover'], axis=1,inplace = True)
df.insert(0, 'turnover', front)
df.head()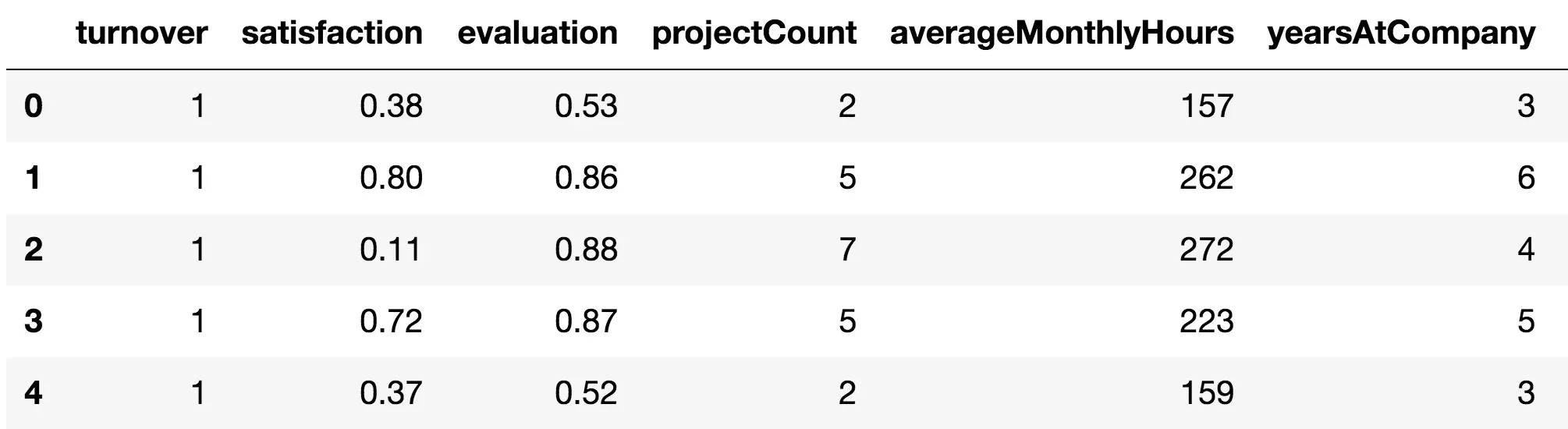
3. Analyzing Data
Đã có cái nhìn tổng quát về dữ liệu, ta bắt đầu tiến hành phân tích thôi :D
3.1. Thống kê tổng quan
- Công ty có khoảng 15,000 nhân viên với 10 features.
>>> df.shape
(14999, 10)- Tỉ lệ bỏ việc khoảng 24%
>>> turnover_rate = df.turnover.value_counts() / 14999
>>> turnover_rate
0 0.761917
1 0.238083
Name: turnover, dtype: float64- Độ thoả mãn trung bình của nhân viên là khoảng 0.61 (với 0 là không thoả mãn, 1 là hoàn toàn thoả mãn)
>>> df.describe()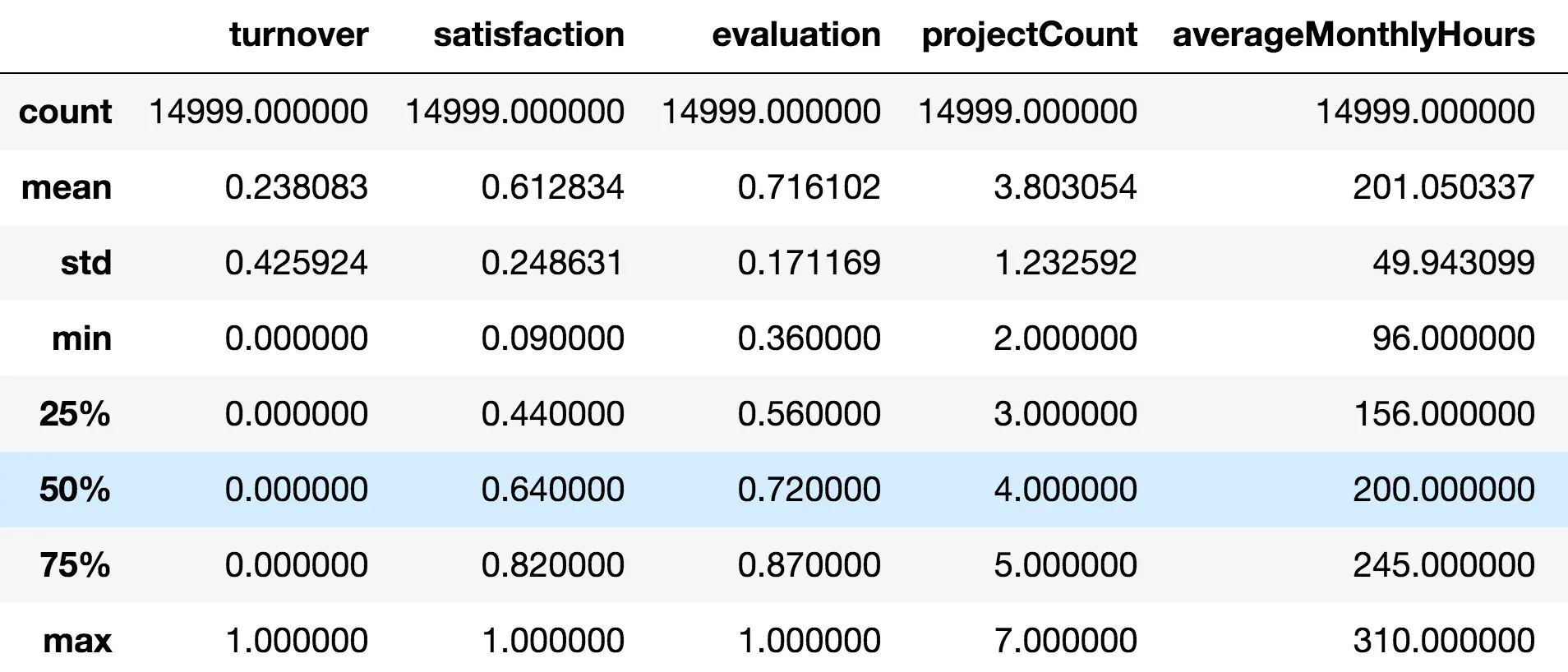
- Những người bỏ việc có độ thoả mãn thấp hơn những người không bỏ việc =)) tất nhiên rồi
>>> turnover_Summary = df.groupby('turnover')
>>> turnover_Summary.mean()
- Phân phối của một số trường quan trọng
f, axes = plt.subplots(ncols=3, figsize=(15, 6))
sns.distplot(df.satisfaction, kde=False, color="g", ax=axes[0]).set_title('Employee Satisfaction Distribution')
sns.distplot(df.evaluation, kde=False, color="r", ax=axes[1]).set_title('Employee Evaluation Distribution')
sns.distplot(df.averageMonthlyHours, kde=False, color="b", ax=axes[2]).set_title('Employee Average Monthly Hours Distribution')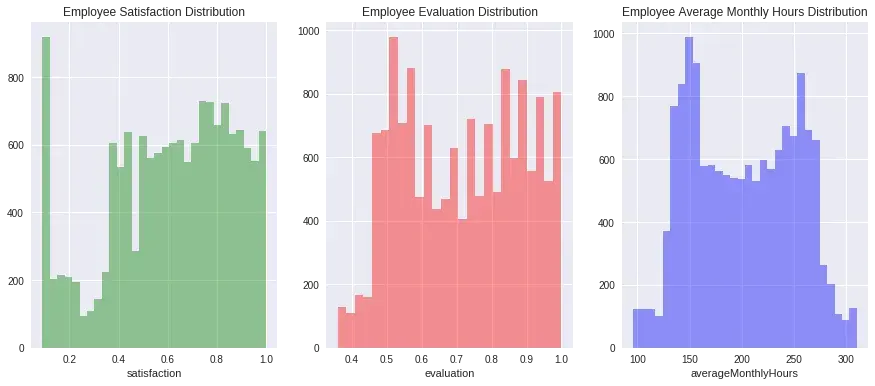
3.2. Ma trận độ tương quan giữa các features
Ta sẽ hiển thị ra ma trận độ tương quan giữa các features.
corr = df.corr()
corr = (corr)
sns.heatmap(corr,
xticklabels=corr.columns.values,
yticklabels=corr.columns.values)
sns.plt.title('Heatmap of Correlation Matrix')
corr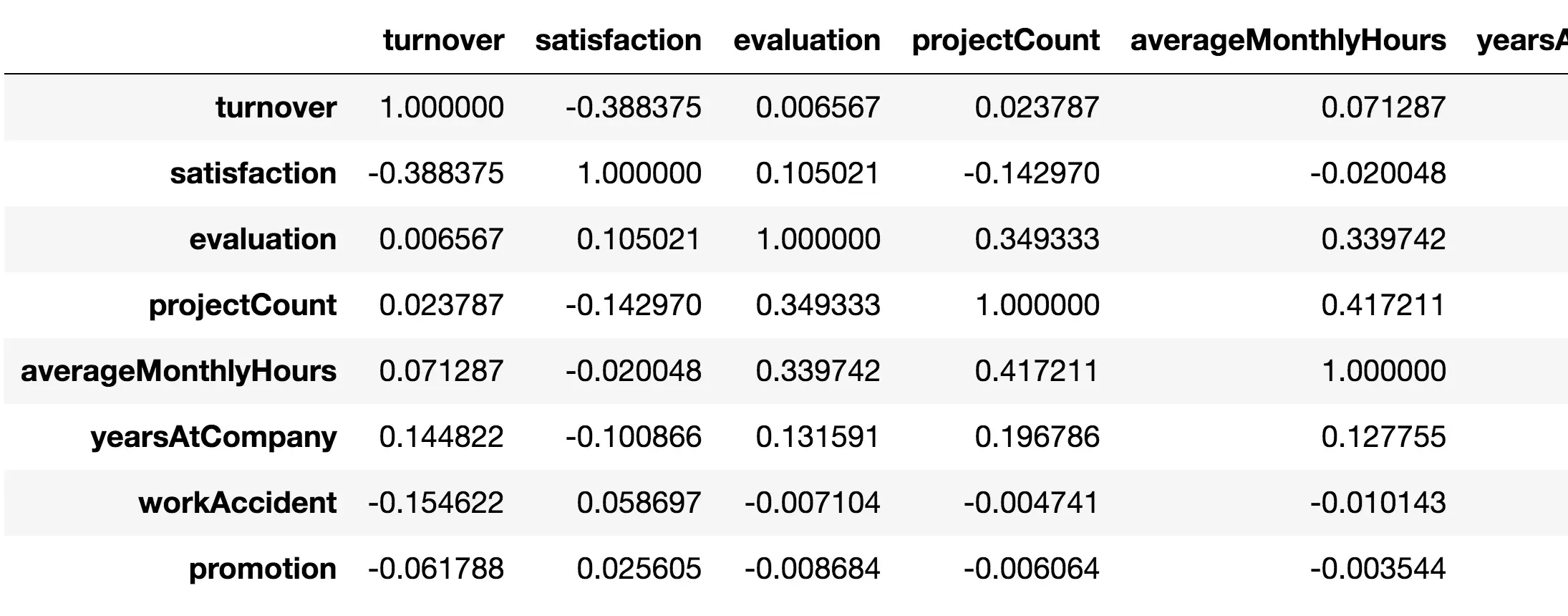
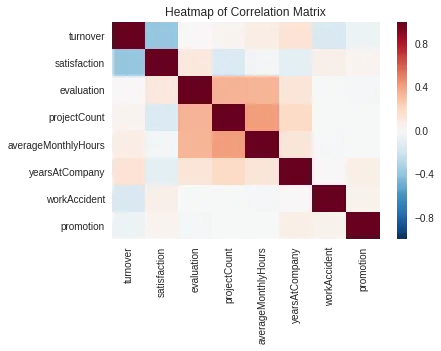
- Những mối tương quan đồng biến (positively correlated) đáng chú ý:
projectCount vs evaluation: 0.349333
projectCount vs averageMonthlyHours: 0.417211
averageMonthlyHours vs evaluation: 0.339742Nó có ý nghĩa rằng những nhân viên dành nhiều thời gian làm việc tại công ty hơn và tham gia nhiều project hơn sẽ được đánh giá cao hơn.
- Những mối tương quan nghịch biến (negatively correlated) đáng chú ý:
satisfaction vs turnover: -0.388375Một sự thật hiển nhiên thôi, càng ít thoả mãn thì khả năng rời đi càng cao.
💡 Suy ngẫm:
- Yếu tố nào ảnh hưởng lớn nhất đến sự ra đi của nhân viên?
- Những yếu tố nào có mối liên hệ chặt chẽ với các yếu tố khác?
3.3. Nghỉ việc vs Lương
Rõ ràng đây luôn là yếu tố đầu tiên và trực diện nhất =))
f, ax = plt.subplots(figsize=(15, 4))
sns.countplot(y="salary", hue='turnover', data=df).set_title('Employee Salary Turnover Distribution');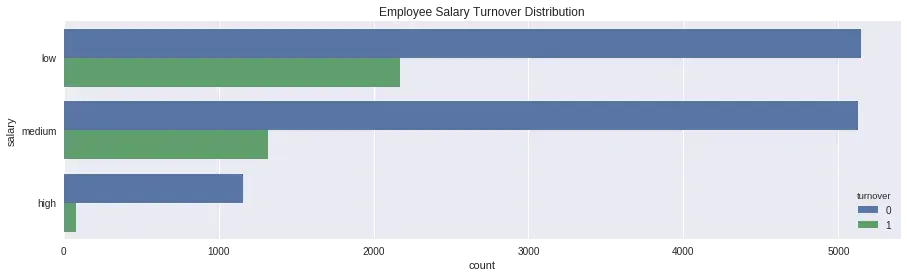
Summary:
- Phần lớn nhân viên ra đi có lương thấp hoặc trung bình
- Những nhân viên có lương cao ít ra đi
💡 Suy ngẫm: Vẫn có những nhân viên lương cao ra đi, lý do vì đâu?
3.4. Nghỉ việc vs Bộ phận làm việc
color_types = ['#78C850','#F08030','#6890F0','#A8B820','#A8A878','#A040A0','#F8D030', '#E0C068','#EE99AC','#C03028','#F85888','#B8A038','#705898','#98D8D8','#7038F8']
sns.countplot(x='department', data=df, palette=color_types).set_title('Employee Department Distribution');
plt.xticks(rotation=-45)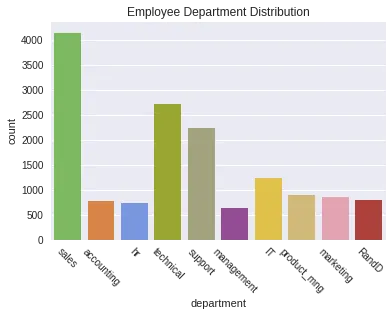
f, ax = plt.subplots(figsize=(15, 5))
sns.countplot(y="department", hue='turnover', data=df).set_title('Employee Department Turnover Distribution');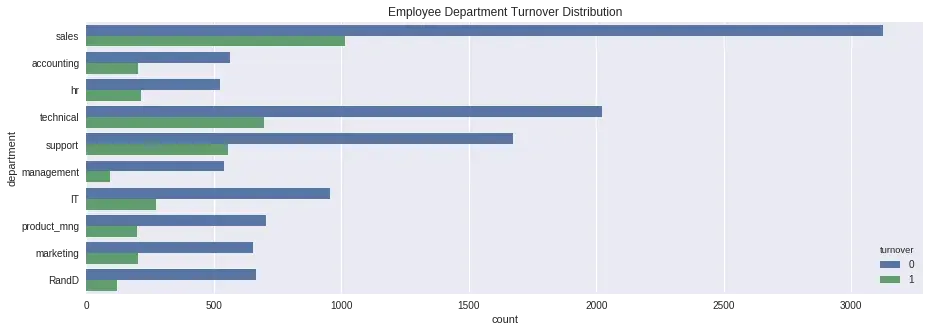 Summary:
Summary:
- Các bộ phận có người nghỉ nhiều nhất là sales, technical và support. Có thể thấy rằng sales và technical là các bộ phận thường xuyên chịu áp lực lớn về doanh số cũng như deadline, còn support thì chịu cảnh làm dâu trăm họ cũng chẳng sung sướng gì.
- Các sếp (bên management) là ít chuyển việc nhất.
3.5. Nghỉ việc vs Số lượng project đã tham gia
ax = sns.barplot(x="projectCount", y="projectCount", hue="turnover", data=df, estimator=lambda x: len(x) / len(df) * 100)
ax.set(ylabel="Percent")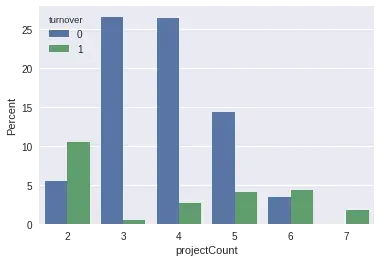 Summary:
Summary:
- Hơn nửa số nhân viên ra đi khi đã làm 2, 6 và 7 projects
- Phần lớn số người không rời công ty khi làm 3, 4, 5 project
- Số làm 7 projects ra đi sạch sẽ
- Có dấu hiệu tăng của tỉ lệ ra đi khi càng làm nhiều project
💡 Suy ngẫm: Những người làm 6+ projects hẳn là những nhân viên lâu năm, phải chăng họ cần thêm điều gì nữa ngoài những projects để tránh khỏi sự nhàm chán mà ra đi?
3.6. Nghỉ việc vs Đánh giá
fig = plt.figure(figsize=(15,4),)
ax=sns.kdeplot(df.loc[(df['turnover'] == 0),'evaluation'] , color='b',shade=True,label='no turnover')
ax=sns.kdeplot(df.loc[(df['turnover'] == 1),'evaluation'] , color='r',shade=True, label='turnover')
plt.title('Employee Evaluation Distribution - Turnover V.S. No Turnover')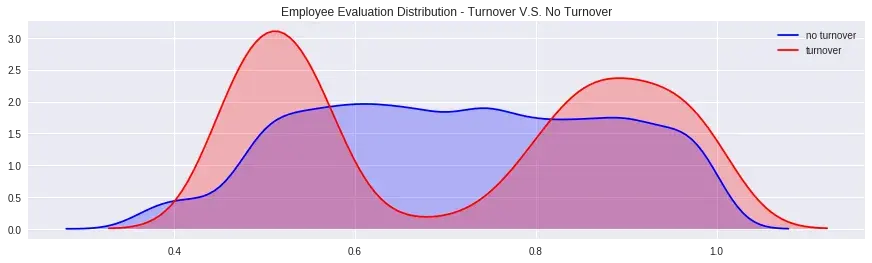 Summary:
Summary:
- Nhân viên được đánh giá thấp quá cũng sẽ ra đi
- Nhân viên được đánh giá cao quá cũng sẽ ra đi
- Nhân viên trung bình và khá, tức mức Evaluation từ 0.6-0.8 là những người ở lại với công ty. Có thể hiểu là với mức đánh giá đó, họ luôn còn mục tiêu để mà cố gắng.
💡 Suy ngẫm: Việc đánh giá thấp nhân viên rõ ràng là không tốt, nhưng việc đánh giá quá cao nhân viên cũng không hề tốt hơn. Tại sao ? mỗi chúng ta đều có những mục tiêu riêng cho mình để phấn đấu, khi con người ảo tưởng rằng mình đã quá ngon, đã perfect, cũng giống như đỉnh cao lạnh lẽo, đâu còn mục tiêu gì mà phấn đấu, nên ra đi là điều không hề kỳ lạ.
3.7. Nghỉ việc vs Thời gian làm việc trung bình trong tháng
fig = plt.figure(figsize=(15,4))
ax=sns.kdeplot(df.loc[(df['turnover'] == 0),'averageMonthlyHours'] , color='b',shade=True, label='no turnover')
ax=sns.kdeplot(df.loc[(df['turnover'] == 1),'averageMonthlyHours'] , color='r',shade=True, label='turnover')
plt.title('Employee AverageMonthly Hours Distribution - Turnover V.S. No Turnover')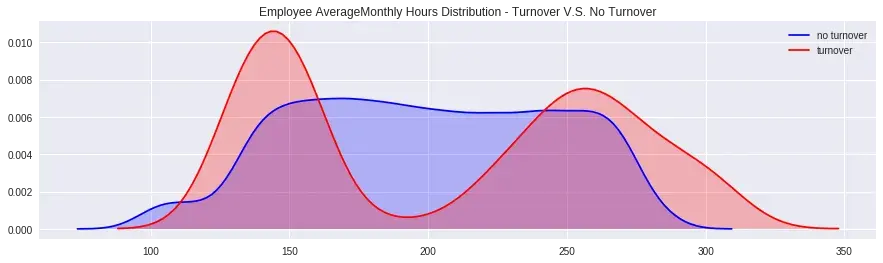 Summary: Sơ đồ gần giống với Evaluation bên trên
Summary: Sơ đồ gần giống với Evaluation bên trên
- Nhân viên làm việc ít hơn 150h/tháng sẽ nghỉ
- Nhân viên làm việc nhiều hơn 250h/tháng sẽ nghỉ
Những điều này dễ hiểu, ngồi chơi không có việc gì để làm, và OT quá độ đều không tốt và dẫn tới sự ra đi của nhân viên. Các sếp hãy tạo điều kiện tốt nhất để ai cũng có việc làm đầy đủ và vui vẻ.
3.8 Đánh giá vs Độ thoả mãn
sns.lmplot(x='satisfaction', y='evaluation', data=df,
fit_reg=False, # No regression line
hue='turnover') # Color by evolution stage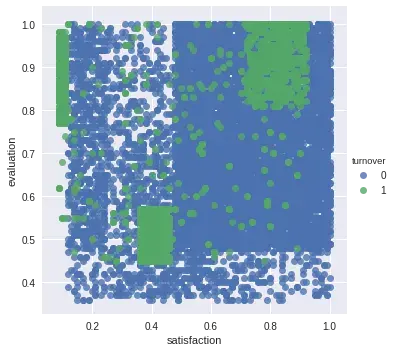 Summary: Có 3 Nhóm nhân viên có xu hướng rời công ty
Summary: Có 3 Nhóm nhân viên có xu hướng rời công ty
-
Nhóm 1 (Hard-working and Sad Employee): là nhóm nhân viên có chỉ số thoả mãn nhỏ hơn 0.2 and và được đánh giá lớn hơn 0.75. Đây là điển hình cho những nhân viên có những tố chất rất tốt, làm việc hiệu quả, nhưng cảm thấy chán nản với công việc mình đang làm.
💡 Suy ngẫm: Điều gì là lý do khiến các nhân viên tốt cảm thấy buồn chán, có phải vì họ phải làm việc quá nhiều hay bản thân nội dung công việc đó nhàm chán ?
-
Nhóm 2 (Bad and Sad Employee): Được đánh giá thấp, độ thoả mãn thấp. Đây là điển hình của nhóm nhân viên kém của công ty.
-
Nhóm 3 (Hard-working and Happy Employee): Độ thoả mãn cao, từ 0.7~1.0 và được đánh giá trên 0.8. Đây là nhóm top-class nhân viên, thật là kỳ lạ!
💡 Suy ngẫm: Có phải họ rời đi vì họ tìm thấy công việc khác tốt hơn ? Thật khó để tìm ra một lý do thoả đáng.
3.9. Sử dụng K-Means Clustering
Ta sẽ sử dụng K-Means Clustering để phân loại một cách định lượng các nhân viên rời đi vào 3 class như trên. Cụ thể:
- Cluster 1 (Blue): Hard-working and Sad Employees
- Cluster 2 (Red): Bad and Sad Employee
- Cluster 3 (Green): Hard-working and Happy Employee
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3,random_state=2)
kmeans.fit(df[df.turnover==1][["satisfaction","evaluation"]])
kmeans_colors = ['green' if c == 0 else 'blue' if c == 2 else 'red' for c in kmeans.labels_]
fig = plt.figure(figsize=(10, 6))
plt.scatter(x="satisfaction",y="evaluation", data=df[df.turnover==1],
alpha=0.25,color = kmeans_colors)
plt.xlabel("Satisfaction")
plt.ylabel("Evaluation")
plt.scatter(x=kmeans.cluster_centers_[:,0],y=kmeans.cluster_centers_[:,1],color="black",marker="X",s=100)
plt.title("Clusters of Employee Turnover")
plt.show()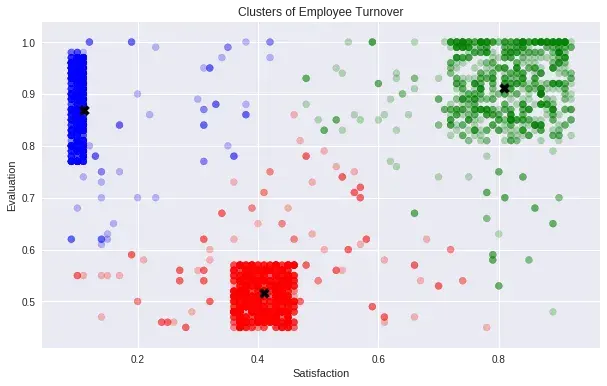
4. Kết luận
- Nhân viên làm ít việc quá sẽ nghỉ việc (ít hơn 150h/tháng hay 6h/ngày)
- Nhân viên làm nhiều việc quá sẽ nghỉ việc (nhiều hơn 250h/tháng hay 10h/ngày)
- Nhân viên có đánh giá quá thấp hay quá cao đều nghỉ.
- Lương thấp và trung bình cũng dễ dẫn tới nghỉ.
- Nhân viên tại các project thứ 2, 6, 7 có nguy cơ cao là nghỉ.
- Yếu tố độ thoả mãn là yếu tố quan trọng nhất quyết định tới việc nhân viên ở lại hay nghỉ.
Đã có rất nhiều điểm đáng chú ý, tuy nhiên dữ liệu là dựng nên vẫn chưa đủ tốt để đánh giá hết các góc cạnh cũng như độ tương quan giữa các yếu tố trong một công ty.
Sẽ cần lắm thêm nữa những dữ liệu nhân sự thực tế của các công ty, để biết đâu nhờ phân tích chúng mà Pham Thị có thể trở thành công ty dẫn đầu về HR Solution trong tương lai. Có thể lắm!
“You don’t build a business. You build people, and people build the business.” - Zig Ziglar